Mainnet postmortems
Mainnet Incident Reports
As part of our day to day job in building eth2 with our Prysm project, we are tasked with maintaining a high integrity cloud deployment that runs several nodes on Ethereum mainnet. Additionally, we are always on call to determine problems which arise in the network and must be addressed by the team. This page outlines a collection of incident reports and their resolutions from catastrophic events on mainnet. We hope it will shed more light on our devops process and how we tackle the hard problems managing a distributed system such as eth2 entails.
Fusaka Mainnet Prysm Incident
Date: 2025/12/04
Status: Resolved
Summary: Nearly all Prysm nodes experienced a resource exhaustion event when attempting to process certain attestations. During this time, Prysm was unable to provide timely responses to validator requests, resulting in missed blocks and attestations.
Impact: The impacted range is considered to be epoch 411439 through 411480. During these 42 epochs, a total of 248 blocks were missing out of 1344 slots. This was an 18.5% missed slot rate. Network participation was as low as 75% during the incident. Validators missed approximately 382 ETH of attestation rewards.
Root Causes: Prysm beacon nodes received attestations from nodes that were possibly out of sync with the network. These attestations referenced a block root from the previous epoch. In order to validate these attestations, Prysm attempted to recreate a beacon state compatible with the out-of-sync node's view of the chain. This resulted in multiple processing of past epoch blocks and expensive epoch transition recomputations. The bug was introduced in Prysm PR 15965 and deployed to testnets a month before the incident without the trigger happening.
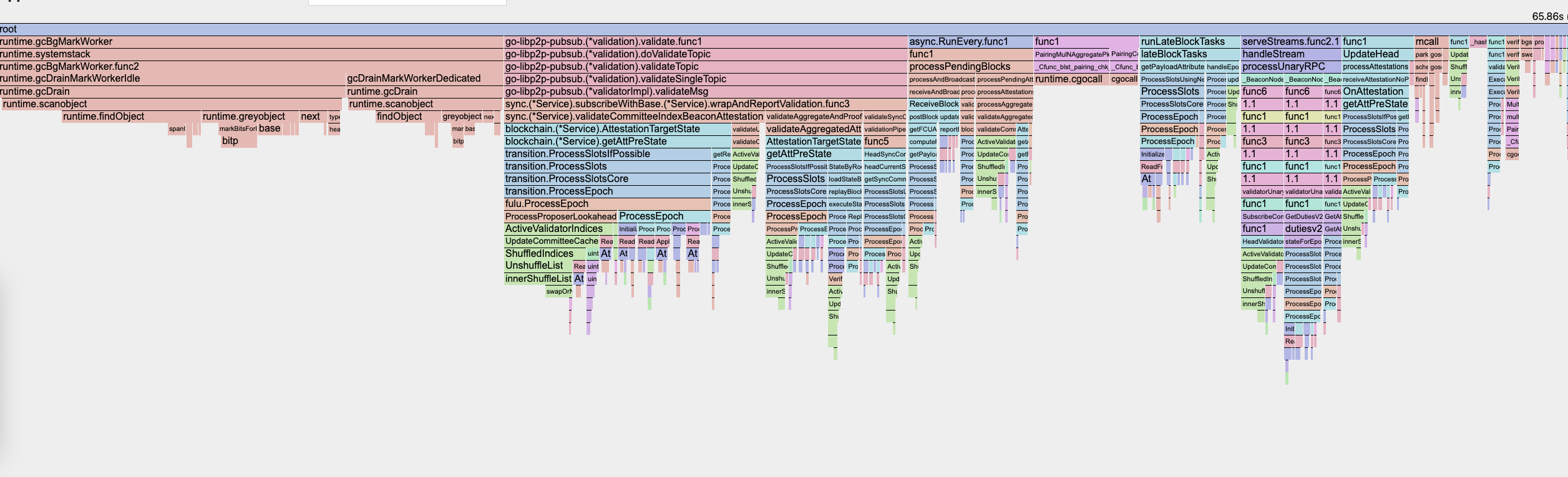
Figure: Profiling a Prysm beacon node shows epoch processing and validator shuffling as the main bottleneck.
Trigger: A specific example is an attestation received in epoch 411442 with a block root of 0xc6e4ff. Block 0xc6e4ff is slot 13166123 from epoch 411441, and it is the 11th block in the epoch. Prysm replayed 11 state transitions and then several empty state transitions with an epoch transition to validate the attestation. We observed this particular attestation behavior 3927 times in our infrastructure. Some nodes in our infrastructure attempted to process attestations for this checkpoint over 700 times concurrently, which led to the client hitting resource exhaustion limits and untimely responses to validator requests.
Resolution: Users were instructed to use the --disable-last-epoch-target flag on their beacon node in v7.0.0. Releases v7.0.1 and v7.1.0 contain a long-term fix where the recommended flag is no longer necessary. The long-term fix changes the attestation verification logic such that the attestation may be verified using the head state without regenerating a prior state. A flag, --ignore-unviable-attestations exists in the new releases, but should not be used. According to the Ethereum Consensus specification, these problematic attestations must be processed and are now correctly using the head state rather than recomputing the state from a prior epoch. Improper use of this new flag could lead to erroneously dropped attestations when the first slot of an epoch is a skipped slot.
Detection: The team received reports from other core developers and end users on all channels that mainnet participation dropped to 75%. Most Prysm users observed low gRPC success rates and high resource usage. The Prometheus metric replay_blocks_count_countt increased at an extremely high rate.
Action Items:
| Action Item | Type | Issue Link |
|---|---|---|
| Deprecate and rename flag --disable-last-epoch-target. | Pull request | PR 16094 |
| Use the head state in cases where Prysm was replaying old states unnecessarily. | Pull request | PR 16095 |
| Move subnet peer log message from WARN level to DEBUG level | Pull request | PR 16087 |
| Publish v7.1.0 minor release | Release | Release v7.1.0 |
| Publish v7.0.1 minor release | Release | Release v7.0.1 |
Lessons Learned
What Went Well
- Client diversity prevented a noticeable impact on Ethereum users. A client with more than 1/3rd of the network would have caused a temporary loss in finality and more missed blocks. A bug client with more than 2/3rd could finalize an invalid chain.
What Went Wrong
- There was a miscommunication about the feature flag. Initially, the team understood that the flag would disable a problematic feature. However, the inverse was true. A new feature was introduced to address the issue, and it was “opt-in,” where users needed to apply the flag for the node to utilize the new feature logic. The original message had the desired outcome, but it was a miscommunication nonetheless.
- As a result, Lighthouse may represent more than 56% of the network (source: Miga Labs via clientdiversity.org, on December 12, 2025). This is dangerously close to the threshold at which a client bug could finalize an invalid chain.
- The bug was not observed during testing, and therefore, the flag was not enabled by default.
Favorable Conditions Encountered
- The workaround was already present in v7.0.0. Prysm did not need to issue an emergency release, and users did not need to download or compile a new version. Adding a flag to their config was the lowest-impact resolution possible.
Possible Testing
- Introduce misbehaving nodes into testing environments with a similar scale to mainnet. The issue only manifests in a large state with many validators out of sync.
Timeline
2025-12-04 (all times UTC)
- ~2:45 - Prysm nodes start having issues.
- 2:50 - Mainnet participation starts dropping to 80%. Blocks are missing from epoch 411439.
- 3:30 - Prysm team receives the first reports about mainnet participation dropping to ~75% and end users reporting their Prysm nodes are “down.” Prysm’s incident response team is activated.
- 3:33 - First public acknowledgement of the issue on Prysm’s Discord server.
- 4:00 - Prysm team analyzes the issue and begins internal testing of potential fixes.
- 4:20 - Prysm team approves workaround to apply a feature flag
--disable-last-epoch-targetto enable a new feature to address the issue. This feature is present in v7.0.0, but not enabled by default. - 4:34 - Public announcements are made on Prysm’s Discord, X account, and other channels to communicate the workaround of using `
--disable-last-epoch-target. Most users report immediate resolution with this flag. - 4:45 - Mainnet participation is above 80% again during epoch 411457.
- 6:00 - Mainnet participation is above 90% again during epoch 411469.
- 7:12 - Mainnet participation is above 95% again during epoch 411480. The incident is considered mitigated as of epoch 411480.
Supporting information
For more information on this incident, study the chain between epochs 411439 and 411480. Additionally, Potuz has written a more technical write-up, which can be found here: potuz.net/posts/fulu-bug/
Ethereum Mainnet Finality
Date: 2023/05/12
Authors: Das, Tsao, Van Loon, Kirkham, He
Status: Mitigated. Investigation complete. Prysm v4.0.4 released with fixes.
Network: Mainnet
Summary: Ethereum's Mainnet network suffered a significant lack of block production which led to a temporary delay (4 epochs) in finalization. The same incident occurred the following day for slightly longer (9 epochs) and incurred an inactivity penalty. In both incidents, the blockchain recovered without any intervention.
Impact: Approximately 47 blocks were missed during the first incident which could be attributed to root cause. In the second incident, approximately 149 blocks were missing. When the lack of finality passed 5 epochs in the second incident, an inactivity penalty started to apply and quadratically increase each epoch. Each block should reward the producer with at least 0.025 ETH on average and the missing blocks represent a total lost revenue of 5 ETH for impacted block producers. However, the true lost revenue is likely much higher if builder bundle rewards are considered. If we assume that 65% of the validators were offline for 8 epochs with an inactivity leak, we estimate that a loss of 28 ETH was incurred in addition to approximately 50 ETH in lost revenue from missing attestations.
In total, we estimate that 28 ETH of penalties were applied and validators missed 55 ETH or more of potential revenue. This is less than 0.00015 ETH per validator.
No validator slashings were attributed to these events, although validators 48607, 48608, and 48609 were slashed slightly before and after the second incident. These slashings were likely due to operator error while switching clients or attempting a complex unsafe failover.
End-user transactions were minimally impacted. While there was a significant drop in available block space, gas prices did not increase higher than the daily highest gas price.
Root causes: Some consensus clients, including Prysm, could not process valid attestations with an old target checkpoint in an optimal way. These specific attestations caused clients to recompute prior beacon states in order to validate that the attestations belonged to the appropriate validator committees. When many of these attestations were received, Prysm would suffer from resource exhaustion from these expensive operations and could not fulfill the requests of the validator clients in a timely manner.
Trigger: Many attestations voting to an old beacon block (that is a block from epoch N-2 during epoch N), both as head block and as a target root, were broadcast. This is a standard behavior of some CL clients (e.g., Lighthouse does this) when their Execution Client is not responding. These attestations, while valid, require a Beacon state regeneration to validate them. Prysm has a cache to not repeat this validations, but this cache was quickly filled up and this forced Prysm to regenerate the same state multiple times.
Detection: A significant drop in network participation was observed in epoch 200,551 and the chain temporarily stopped finalizing until epoch 200,555.
Another significant drop in network participation was observed in epoch 200,750 and the chain temporarily stopped finalizing until epoch 200,759.
What went wrong:
- The network was failing to finalize due to missing blocks and attestations.
- Beacon chain clients had additional stress on the network caused by max deposits being processed.
- In Prysm, too many replays (
replayBlocksfunction) happen because we do not have a cache for replays. This was also what created all the go routines and CPU usage. Sometimes the same data would be replayed multiple times. Sometimes the replay is happening even before the first finished. Should be ignoring attestations at the previous epoch, and should be using head state. - There is a bug in Prysm: nodes that are connected to all subnets can be DOSsed by these attestations (it seems that all nodes are subject to this, probably except Lighthouse) as the cost of being resilient to forked networks. When the beacon state was smaller, Prysm would be able to handle these attestations and recover appropriately. However, with the large spike in deposits and the growing validator registry size Prysm was unable to recover this time. Lighthouse opted to drop attestations in order to stay live, we opted to be able to keep many forks at the same time in order to be able to pick correctly a canonical chain in case the network is very forked. Lighthouse's technique is better here because the network is not forked. They simply dropped attestations and followed the chain. If the network would have been forked, we would have been in trouble cause then Lighthouse would be contributing to not gossiping attestations.
- Some client default attestation behavior is to produce valid blocks with old attestations when the execution client has issues or is offline. other clients may deal with this differently such as considering the situation as optimistic sync. This can create blocks with old attestations triggering the issues in Prysm and Teku.
Where we got lucky:
- In the first incident, the duration of downtime was only 2 epochs reaching finality after 25 minutes. The second incident was also relatively short with only 8 epochs of symptoms. No mass slashings were reported in either incident.
- Client diversity helped the chain recover with some clients still being able to propose blocks and create attestations.
- Lighthouse dropped the problematic attestations and stayed alive.
- No manual intervention or emergency release was required to resolve the immediate issue finality issue.
Lessons learned
- Testnets are not representative of the Mainnet environment. Goerli/Prater is only 457k validators while Mainnet is more than 560k and mass deposits are happening in Mainnet due to validator rewards restaking.
- Inactivity leak penalties work in Mainnet!
Fixes implemented:
- Use the head state when validating attestations for a recent canonical block as target root. This was the main bug! Prysm was regenerating the state for canonical slot 25 if used as target root on epoch 1 during slot 33.
- Use the next slot each cache when validating attestations for boundary slots in the previous epoch.
- Discard any attestations that weren’t validated by the previous two rules and are for a target root that is not a checkpoint in any chain that we are currently aware of, and is not the tip of any chain that we are currently aware of (They will be processed if included in blocks).
- With the above rules, there are essentially no state replays that need to be done on Mainnet under normal conditions, and those attestations for old blocks (which are mostly worthless to the network) are just ignored.
Timeline (approximate)
2023/05/11 Thursday (UTC)
20:06:47 — Epoch 200,551 begins, there is a missed/orphaned block and a few missed slots, and network participation drops to 88.4%
20:13:11 — Epoch 200,552 begins and there are more missed slots in this epoch, network participation drops to 69%
20:19:35 — Epoch 200553 begins. Gradually more and more consecutive slots were missed causing a total of 18/32 slots to missed and not finalizing the block. The most consecutive misses between slots 6417716 ~ 6417709. Network participation is at a low of 40%. It is clear that this isn’t just a Prysm issue as Prysm represents only 33% of the network.
20:29:00 — Prysm team is all hands on deck with an investigation of ongoing issues.
20:32:23 — Epoch 200555 starts and the network begins to recover without intervention.
2023/05/12 Friday (UTC)
17:20:23 — Epoch 200750 begins. Blocks are missing at an increasing rate and participation drops to 66.3%.
17:26:47 — Epoch 200751 begins. Only 13 out of 32 blocks are produced. Participation drops to 42.4%.
17:30:00 — “Mainnet stopped finalizing again”. All hands on deck.
17:33:11 — Epoch 200752 begins. Only 14 blocks are produced. Participation drops further to 30.7%. This is the lowest participation of any epoch in Mainnet ever.
18:17:59 — Epoch 200759 begins. 24 of 32 blocks are produced and participation is 81.7%. This epoch is the start of recovery.
18:24:23 — Epoch 200760 begins. 27 of 32 blocks are produced with 86.2% participation. This epoch restores finalization.